标题党了,其实是论VIM的使用。
做生物信息分析最合适的还是Linux操作系统,所以生信宝典在最开始就推出了Linux学习系列,由浅入深的讲述了Linux学习中的关键点。
主要文章列举如下:
- Linux学习-文件和目录
- Linux学习-文件操作
- Linux文件内容操作
- Linux学习-环境变量和可执行属性
- Linux学习 - 管道、标准输入输出
- Linux学习 - 命令运行监测和软件安装
- Linux学习-常见错误和快捷操作
- Linux学习-文件列太多,很难识别想要的信息在哪列;别焦急,看这里。
- Linux学习-文件排序和FASTA文件操作
- 用了Docker,妈妈再也不担心我的软件安装了 - 基础篇
- Linux服务器数据定期同步和备份方式
但有时也需要在Windows下做一些操作,可能是Linux当前不可用,也可能不值得折腾。
实现Linux下复杂而又简便的操作,VIM配合正则表达式是一个合适的选择。
VIM是一款功能强大的文本编辑工具,也是我在Linux,Windows下编辑程序和文本最常用的工具。
初识VIM
VIM分多种状态模式,写入模式,正常模式,可视化模式。
正常模式:打开或新建文件默认在正常模式,可以浏览,但不可以写入内容。这个模式也可以称作命令行模式,这个模式下可以使用VIM强大的命令行和快捷键功能。其它模式下按ESC就可以到正常模式。写入模式:在正常模式下按字母i(光标前插入),o(当前光标的下一行操作),O(当前光标的上一行操作),a(光标后插入)都可以进入写入模式,就可以输入内容了。可视化模式:通常用于选择特定的内容。
进入写入模式后,VIM使用起来可以跟记事本一样了。在写入文字时,可以利用组合键CTRL+n和CTRL+p完成写作单词的自动匹配补全,从而加快输入速度,保证输入的前后一致。
正常模式有更强大的快捷键编辑功能,把手从鼠标上解放出来。
dd: 删除一行3dd: 删除一行dw: 删除一个单词d3w: 删除3个单词yy: 复制一行3yy: 复制三行yw: 复制一个单词p: (小写p)粘贴到下一行P: (大写P)粘贴到上一行>>: 当前行右缩进一个TAB3>>: 当前行及后2行都向右缩进一个TAB<<: 当前行左缩进一个TAB3<<: 当前行及后2行都向左缩进一个TAB-
/word: 查找特定单词 u: 撤销上一次操作.: 重复上一次操作-
CTRL+r: 重做撤销的操作 y$: 从当前复制到行尾d$: 从当前删除到行尾
跳转操作
gg: 跳到文件开头G: 跳到文件结尾zt: 当前行作为可视屏幕的第一行5G: 跳到第5行
正常模式下输入冒号进入更强大的命令行定制功能。
:5d: 删除第5行:20,24y:复制20到24行:.,+3y:复制当前行和下面3行:2,11>: 右缩进:w: 保存文件-
:q: 退出编辑器 :vsplit: 分屏
键盘操作不容易被捕获,看右下角可以得到一点信息。

VIM还有不少魔性操作,具体可以看这两个帖子:
VIM中使用正则表达式
这儿以提取生信宝典公众号中发过的原创文章的HTML代码为例子,获得原创文章的名字和链接,用以制作文章列表。
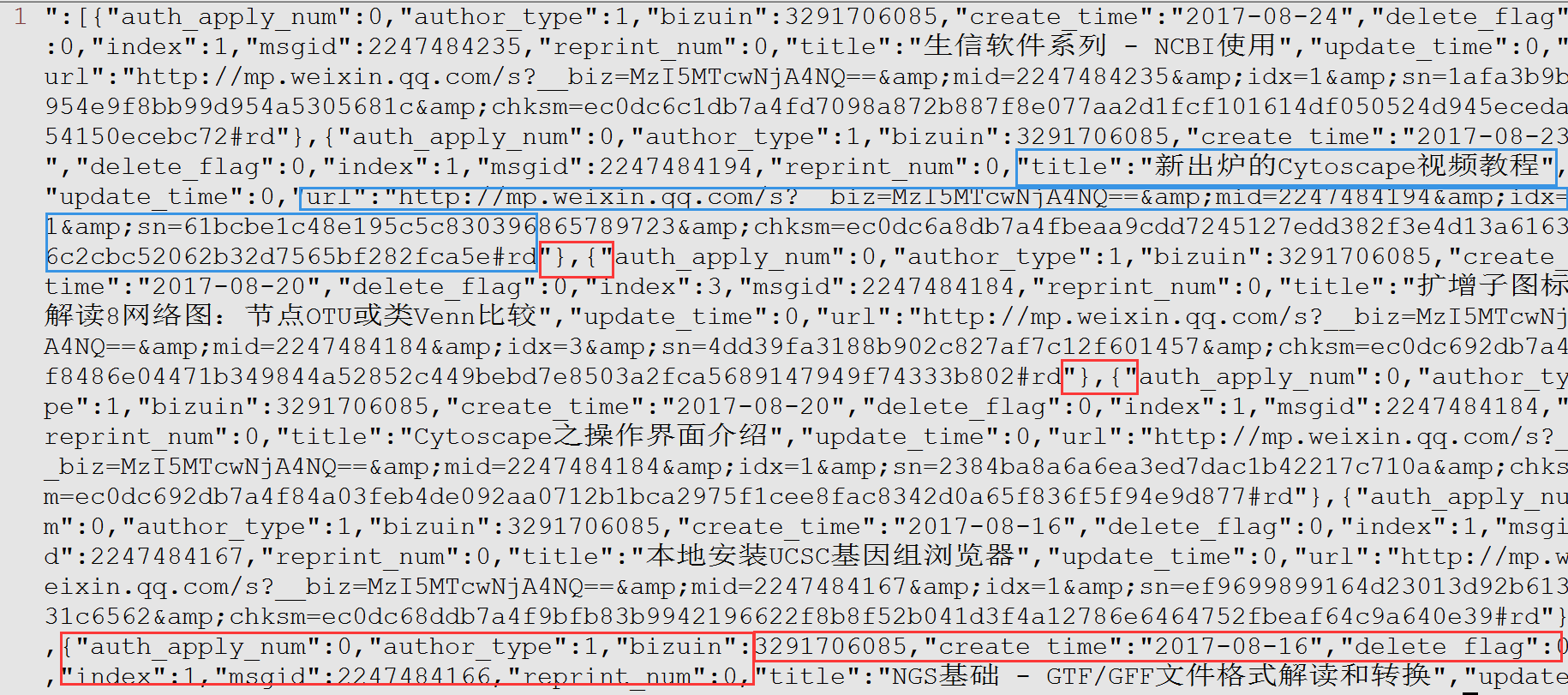
部分数据如下所示,利用正则表达式的第一步就是找规律。
- 这段文字是JSON格式,列表和字典的组合,使用
json函数可以很容易解析。但我们这通过正则表达式解析。 title后面跟随的文章的题目;url后面跟随的是文章的链接。{"和"}标记每篇文章的信息的开始和结束。auth_apply_num是目前不关注的信息。
下面的动画展示了如何通过正则表达式,把这段文字只保留题目和链接,并转成Markdown的格式。
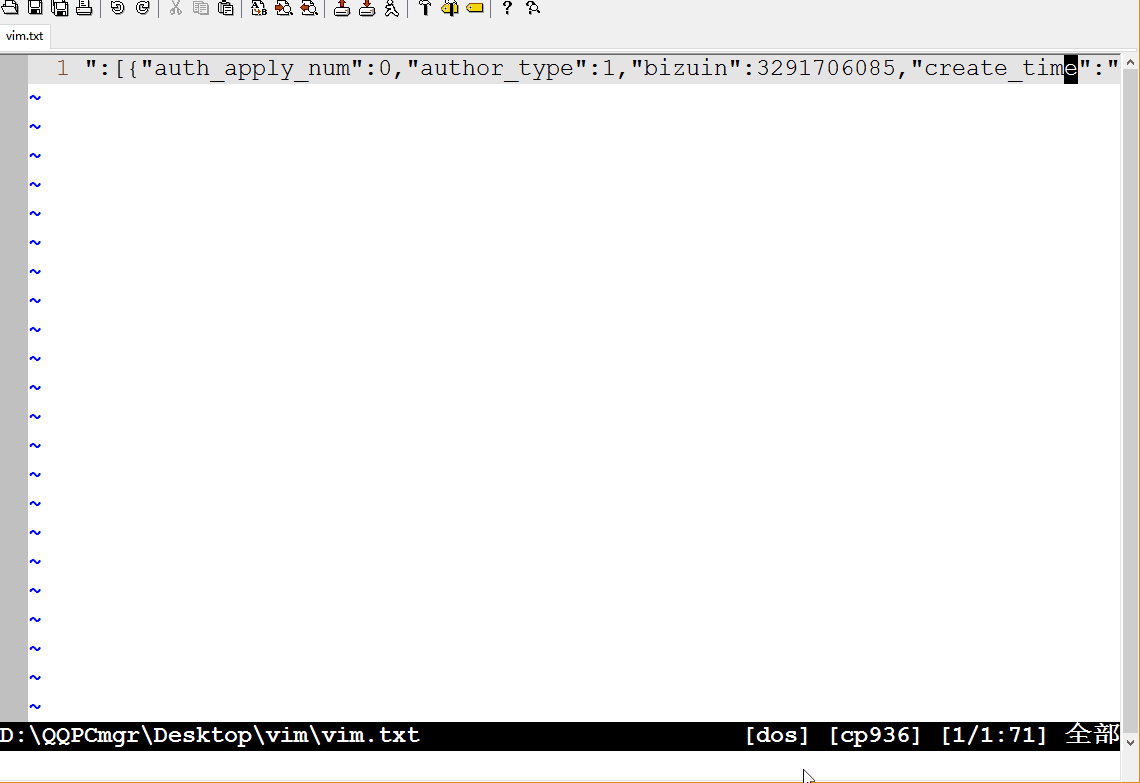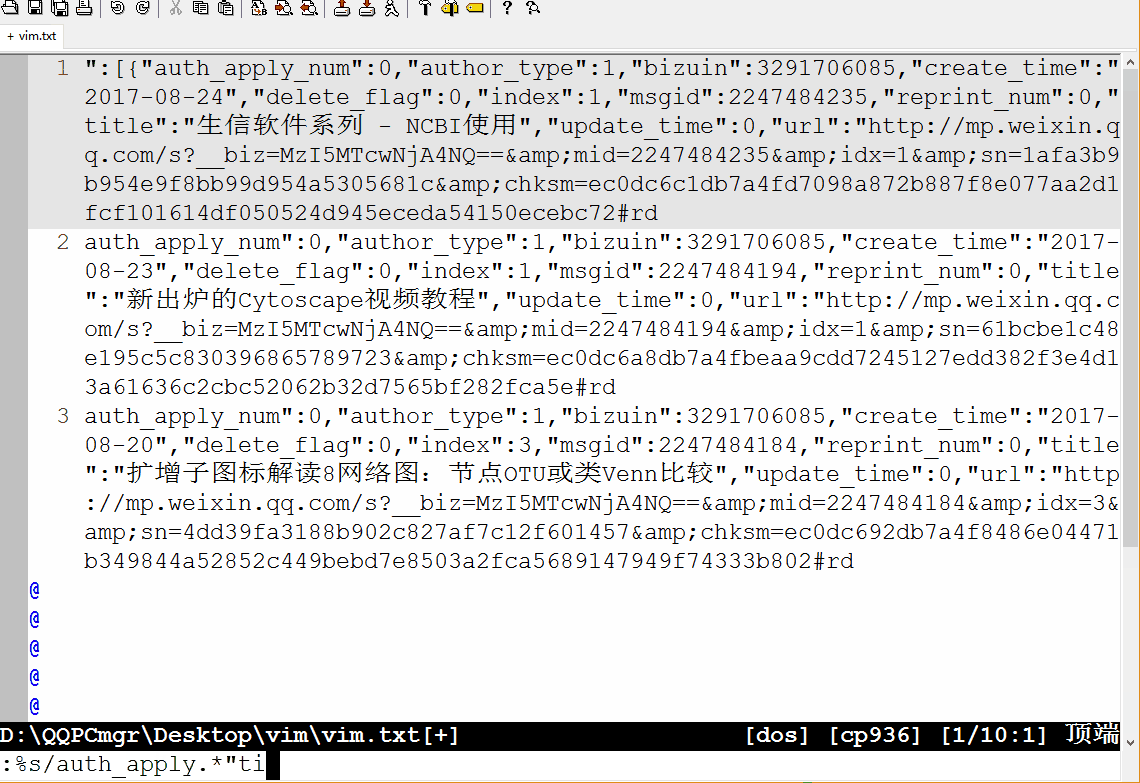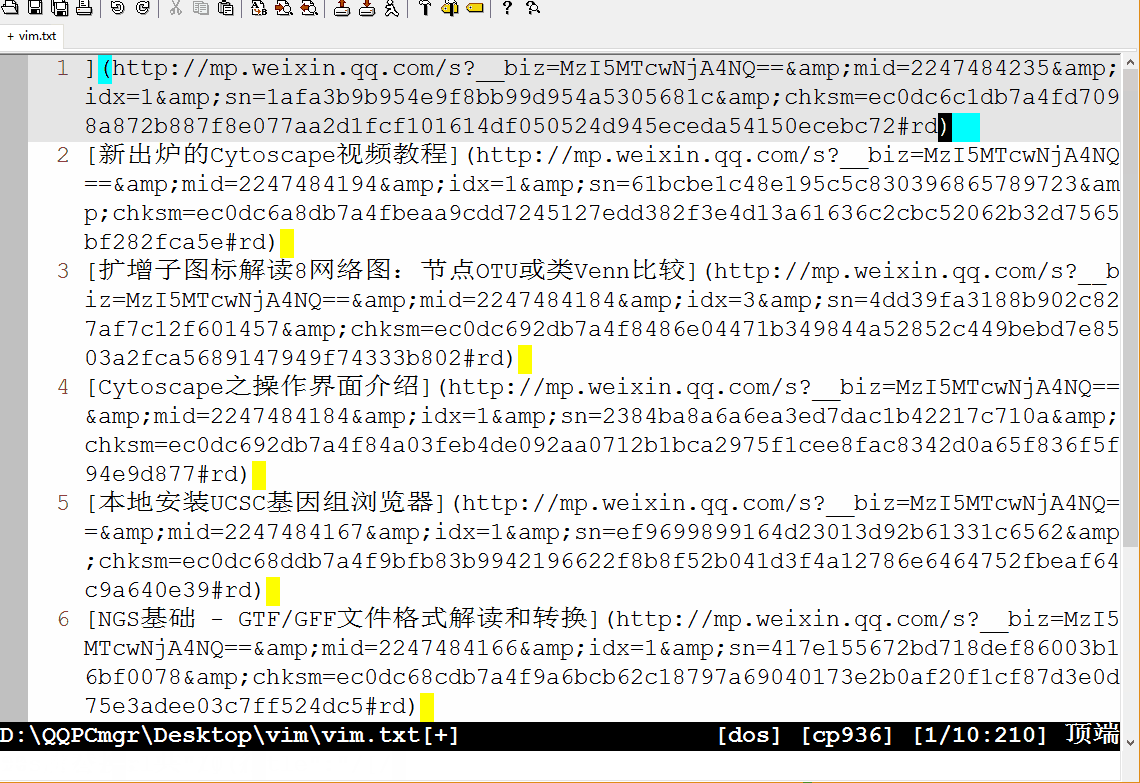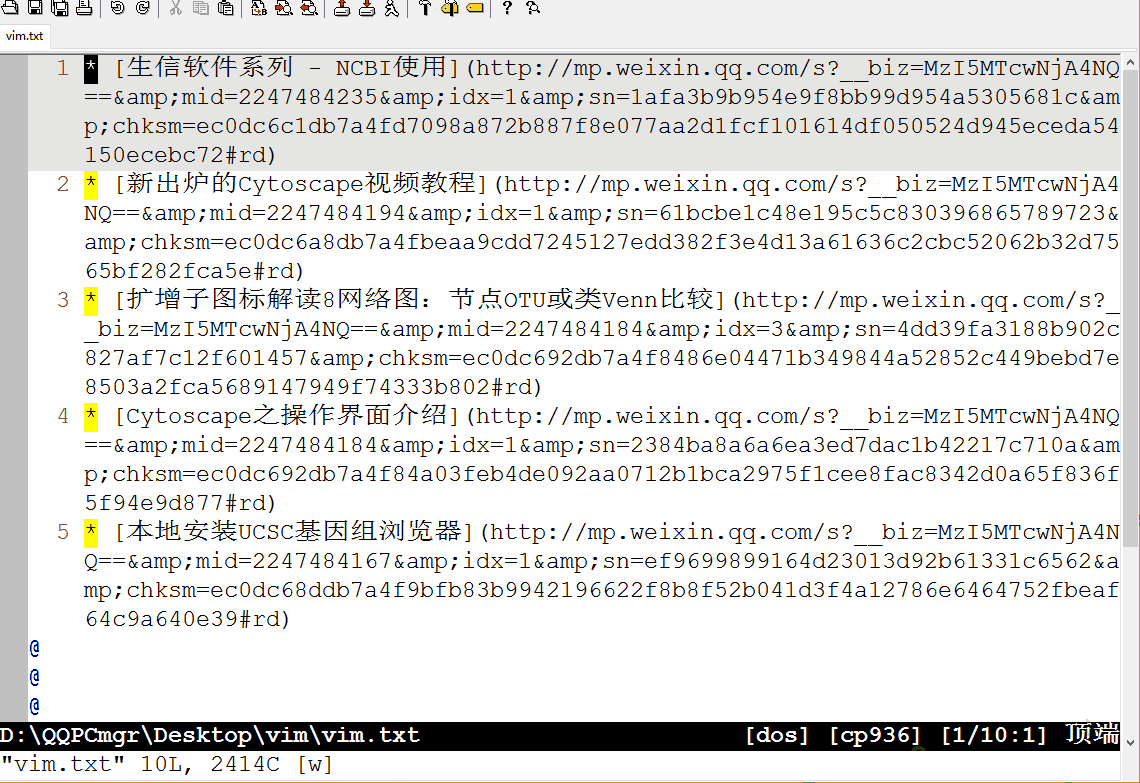
:set wrap: 折行显示:s/"}, {"/\r/g::开启命令行模式;s: 是替换,之前讲Linux命令时也多次提及;/作为分割符,三个一起出现,前两个/中的内容为被替换内容,后两个/中的内容为替换成的内容;这里没有使用正则表达式,直接是原字符的替换,\r表示换行符。这样把每篇文章的信息单行显示,方便后续处理。:%s/auth_apply.*"title":"/[/:%表示对所有行进行操作;被替换的内容是auth_apply和title":"及其之间的内容(.*表示,.表示任意字符,*表示其前面的字符出现任意次):%s/".*"url":"/](/:从题目到url之间的内容替换掉;第一次替换时忘记了第一行中开头还有引号,结果出现了误操作,后面又退回去,手动删除特殊部分,其它部分继续匹配。:%s/$/)/:表示在行尾($)加上), 就组成了Markdown中完整的链接形式[context](link)。:%s/^/* /:表示在行首(^)加上*变成Markdown格式的列表
至此就完成了生信宝典公众号文章到Markdown链接的转换,可以放到菜单栏文章集锦里面方便快速查询了。
一步步的处理也有些麻烦,有没有办法更简单些呢?

- 首先也是把每篇文章的信息处理为单行显示,一样的模式更容易操作,去掉第一行行首不一致的部分
- 使用上下箭头可以回溯之前的命令,类似于Linux终端下的操作
%s/.*title":"\([^"]*\).*url":"\(.*\)/* [\1](\2)/c: 这个是记忆匹配,记录下匹配的内容用于替换,\(和\)表示记忆匹配的开始和结束,自身不匹配任何字符,只做标记使用;从左只右, 第一个\(中的内容记录为\1, 第二个\(中的内容记录为\2,以此类推。尤其在存在括号嵌套的情况下,注意匹配位置,左括号出现的顺序为准。在匹配文章题目时使用了[^"]*而不是.*,是考虑到正则表达式的匹配是贪婪的,会囊括更多的内容进来,就有可能出现非预期情况,所以做这么个限定,匹配所有非"内容。
正则表达式在数据分析中有很多灵活的应用,可以解决复杂的字符串抽提工作。常用的程序语言或命令如pytho, R, grep, awk, sed都支持正则表达式操作,语法也大体相似。进一步学习可参考一下链接: